Web scraping bisa didefinisikan sebagai kegiatan pengambilan atau pengumpulan data dari sebuah website. Proses ini terbagi dua, metode penyalinan data secara manual satu persatu atau otomatis menggunakan bot dan aplikasi untuk menyalin data spesifik yang diinginkan dari sebuah website ke database lokal atau file spreadsheet. Nantinya data-data tersebut akan dipakai untuk sebuah analisa. Tentunya pada artikel ini kita akan membicarakan proses web scraping secara otomatis karena kita orang IT 😁
Manfaat Web Scraping
Seperti yang disebutkan di awal artikel, inti dari web scraping ini adalah data yang berhasil dikumpulkan. Selama data itu ada di sebuat website, secara teori, dapat disalin, tapi apakah kita berhasil mendapatkan data dengan jumlah yang diinginkan. Ini lah yang menentukan seberapa manfaat dari web scraping.
Riset pasar.
Bagi pemilik bisnis, walaupun hanya sekelas UKM, sangatlah penting untuk bisa mencari informasi mengenai produk kompetitor. Melakukan riset pada e-commerce website bisa memberikan banyak informasi seperti harga, popularitas, review dari sebuah produk. Apabila kita bisa mendapatkan data ini dari beberapa website maka mempermudah kita menganalisa produk-produk saingan dan memperhatikan popularitas dan review.
Analisa sentimen.
Untuk mengetahui sentimen masyarakat terhadap sebuah topik atau barang. Data yang akan dikumpulkan adalah data dari media sosial atau forum online dimana orang dengan bebas memberikan komen dan pendapat. Contohnya pada event pemilu, para calon peserta pemilu bisa mengetahui popularitas dirinya dari kumpulan komen dan pendapat di internet.
Marketing.
Bagi pebisnis, sangatlah ingin untuk memiliki daftar kontak calon-calon pembeli produk yang mereka tawarkan. Daftar kontak ini tersebar luas di internet, sebagai contoh, sebuah perusahaan yang memiliki website pasti akan mencantumkan detail kontak mereka. Dengan menggunakan web scrapping, akan kita bisa menyalin kontak perusahaan-perusahaan sejenis secara otomatis dalam waktu yang cepat.
Cara Melakukan Web Scraping
Banyak cara untuk melakukan web scraping. Bagi yang mengerti pemrograman, bisa membuat aplikasi untuk melakukan web scraping; terutama Phyton yang memiliki pustaka open-source besar, membuat penulisan kode pemrograman jadi lebih mudah. Tapi buat yang tidak ada keahlian programming, bisa memakai aplikasi yang tersedia banyak di internet. Cukup untuk memberitahu website yang mau kita analisa dan data mana yang mau diambil maka aplikasi itu akan bekerja mengumpulkan informasi yang kita inginkan. Contoh aplikasi untuk web scraping adalah ScrapingBee, Octoparse, import.io, dan lainnya.
Apakah Legal?
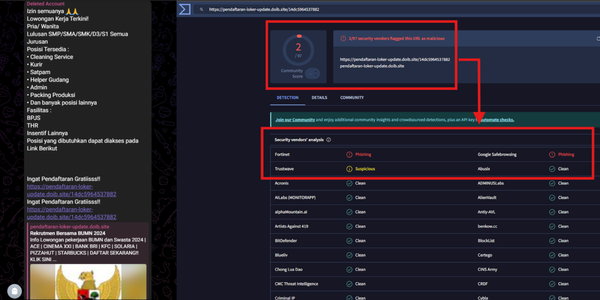
Web scraping sebenarnya bermain di area abu-abu. Pada dasarnya, semua informasi yang ada di internet adalah untuk konsumsi bebas, tidak ada hukum yang menyatakan bahwa menyalin data-data yang berada di internet itu adalah kegiatan ilegal. Kegiatan web scraping ini sebenarnya yang dilakukan search engine untuk pengindeksan. Tapi begitu si pemilik data membuat syarat dan ketentuan untuk tidak melakukan web scraping, biasanya pada website yang memerlukan registrasi untuk mengakses, maka akan ada dasar hukum yang melarang pengguna terdaftar untuk melakukan penyalinan data. Walaupun tidak dilarang, sebenarnya ada etika untuk melakukan web-scraping. Proses web-scraping itu sebenarnya sangat menambah beban akses ke website yang dituju karena adanya akses secara kontinyu dengan jeda waktu yang pendek. Mungkin untuk website besar seperti Amazon, Tokopedia tidak terlalu terganggu oleh "serangan" web scraper ini karena bisa menangani akses banyak, tapi tidak demikan dengan website yang lebih kecil, kemungkinan akan crash karena tidak didesain untuk lalu lintas tinggi. Oleh sebab itu, banyak website yang mengamankan data mereka agar tidak diambil oleh para penjelajah website.
Mengamankan Website dari Web-Scraping
Salah satu efek negatif dari web scraping adalah pencurian konten. Para kriminal siber mencuri konten sebuah website untuk membuat replika yang sama persis untuk tujuan jahat. Bagi pihak yang sangat peduli dengan efek negatif dari web-scraping bisa melakukan langkah berikut untuk pengamanan.
- Monitor lalu lintas network yang masuk.
Dengan mengecek pola dan juga logs serta mendeteksi lalu lintas yang anomali, bisa dilakukan tindakan pemblokiran. - Membatasi akses.
Dengan cara mensyaratkan proses registrasi dan login untuk bisa mengakses website. - Menggunakan Captcha.
Captcha gunanya untuk mengidentifikasi bahwa pengakses website tersebut adalah manusia, bukan robot. Apabila tidak teridentifikasi sebagai manusia maka akan dilakukan pemblokiran akses. - Membuat perangkat honeypots.
Perangkap honeypot adalah bagian dari website yang tidak terlihat oleh pengakses. Tapi karena ciri khas aplikasi web scraping yang mengakses semua bagian dari sebuah website, begitu mengakses honeypot maka akan memberitahu admin website akan adanya tamu tak diundang.